
Fantasy Sumo Predictions
I started watching sumo in 2020. It’s been great, it’s a fun thing to have on in the background. I’ve gotten to see the end of the GOAT Hakuho’s career, Terunofuji’s Yokozuna run, and now the rise of new guys. Other than being drawn to the sound of meat slapping for eight hours straight for two weeks every two months, I also enjoy the different structures of sumo. All of the separate divisions and the East/West standings make it particularly interesting from a data analysis perspective.
Of course, as the title suggests, I’ve gotten into fantasy sumo.
The League Format
You’ll have 5 wrestlers on your team, each from a different rank set:
1 from the yokozuna/ozeki ranks
1 from the sekiwake/komusubi ranks
1 from maegashira 1-5
1 from maegashira 6-10
1 from maegashira 11+
Multiple people can have the same wrestler, but there are limits to keep it interesting. Therefore, when submitting your picks, choose 3 guys from each set.
Points will be granted in the following ways:
1 pt. for each win
5 pts. for the championship or yusho
3 pts for the runner-up, or jun-yusho
3 pts for a special prize, or sansho
2 pts for a gold star victory, or kinboshi
1 pt. for a winning record, or kachi-koshi
-.5 pt. for a losing record, or make-koshi
-.5 pt. for your second trade
-1 pt. for every trade beyond the first 2
So a relatively simple format. We pick three wrestlers from each of the tiers and they get a score based on how well they do. I haven’t really done much trading once the league began automatically trading wrestlers who got hurt, so we’ll ignore that for now in this project. Though, it could be an interesting thing to track during the tournaments and would give me a reason to create a live dashboard. But we’ll save that for another time.
The Data
Our predictions are built on a rich dataset scraped from the incredible SumoDB. SumoDB has data all the way back to the October 1757 tournament which is absolutely incredible. Now, understandably, this data is not as complete as the modern data, and simply features the Makuuchi and Juryo banzukes. By 1761, SumoDB has final results, and by 1909 it has daily results and matchups. Then by 1927, kimarites (winning techniques) are starting to be added for the top divisions. The most complete data begins in the July 1991 tournament, with 2747 kimarites and bouts recorded.
The data comes in two main forms:
- Banzuke Data: This is the official ranking sheet for each tournament. It gives us a wrestler’s rank, stable, age, height, and weight. This is our foundational data.
- Match History Data: This is a detailed, day-by-day log of every match, including the winner, loser, and the kimarite (winning technique).
Combining these two sources allows us to build a deep understanding of each wrestler.
Feature Engineering
Having this rich dataset from SumoDB is great, but in order to properly build a model we need feature engineering.
Here are some of the key features that power the model:
1. Rank Based Features
absolute_rank_score: Absolute rank in the entire sumo structurerank_gap: The difference between a wrestler’s current rank and their career-best rank. This tells us if they’re at their peak, in a slump, or on the rise.
2. Momentum is Key
A wrestler’s recent form is a huge predictor of future success.
kachi_koshi_streak: How many consecutive tournaments has this wrestler had a winning record? A long streak indicates confidence and form.was_kyujo_last_basho: A simple flag to show if a wrestler is returning from an injury-related absence, a major performance factor.
3. Context and Competition
No wrestler competes in a vacuum.
heya_strength: We measure the average rank of a wrestler’s stablemates. A stronger stable means better training partners.division_strength: We also measure the average rank of their opponents in the division. This tells the model how tough the competition is for that specific tournament.
4. The Kimarite Features
This is where we get into advanced analytics by using the detailed match history.
oshi_ratio: The ratio of a wrestler’s wins by “pushing/thrusting” vs. “grappling/belt” techniques. This creates a “fighter style” profile. Is he a pusher or a grappler?avg_h2h_win_pct: The most powerful feature of all. For each wrestler, we calculate their historical head-to-head win percentage against every other opponent they will face in the upcoming tournament.
The “Committee of Experts”: A Stacking Model
No single machine learning model is perfect. To get the best results, we use an ensemble technique called stacking.
- Base Models: We first train three powerful and diverse models on the data: LightGBM, XGBoost, and Random Forest. Each one learns the patterns in the data slightly differently.
- Meta-Learner: We then train a final, simpler model (a Ridge Regressor) whose only job is to learn from the predictions of the three base models. It acts like a “committee chairman,” learning how to best weigh the “opinions” of its expert members to make a final, more accurate prediction.
The Payoff: An Interactive Prediction Report
--- Stacking Model Performance ---
R-squared (R²): 0.1236
Mean Absolute Error (MAE): 2.0059 wins
-----------------------------------
Now sure 0.12 R-squared isn’t great, but I think the MAE of ~2 wins is definitely usable in this context. If we take these win predictions and use them to find the other fantasy sumo stats like kachi-koshis and kinboshis through probability, we should have a workable cheat seet to draft from.
Here are how the various features perform in their current state:
--- Feature Importance (from Final Model) ---
Feature Importance
17 avg_h2h_win_pct 0.092929
6 age 0.092192
10 win_consistency 0.088770
16 avg_opponent_oshi_ratio 0.086453
14 division_strength 0.077871
7 bmi 0.077713
1 rank_in_division 0.073764
8 heya_strength 0.073553
15 oshi_ratio 0.070605
11 rank_gap 0.061180
3 prev_rank_in_division 0.060865
4 prev_w 0.038962
5 prev_l 0.037961
13 kachi_koshi_streak 0.026747
12 was_kyujo_last_basho 0.023008
9 Has_university_sumo 0.008108
2 prev_division_numeric 0.007003
0 division_numeric 0.002317
The final output is a dynamic HTML report that serves as the ultimate fantasy sumo cheat sheet.
Here are the predictions for the upcoming January 2026 tournament:
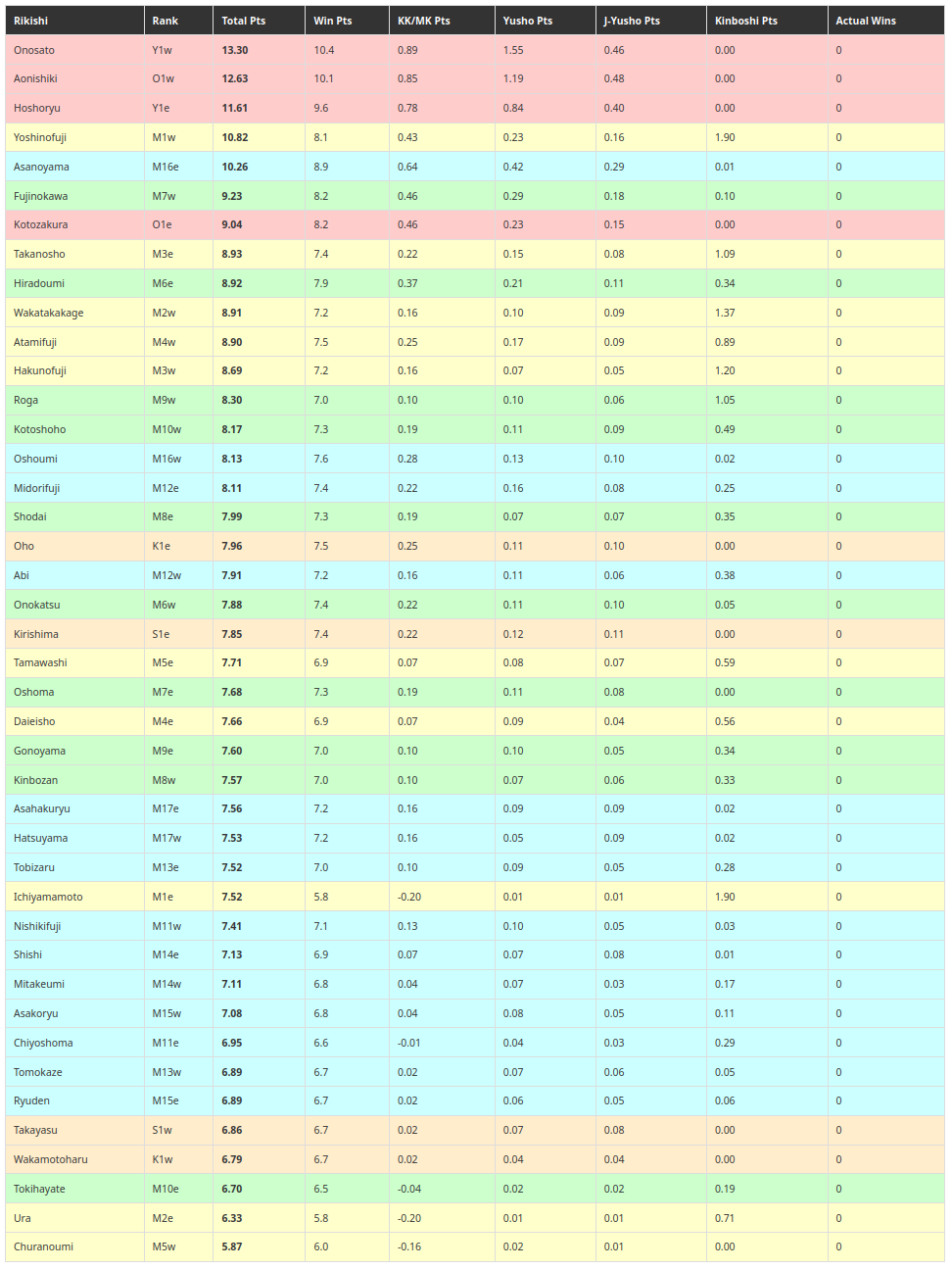
By combining deep domain knowledge with modern machine learning techniques, this project transforms raw sumo data into a powerful and insightful prediction engine for a particular fantasy sumo league.